01
Step 1 of 5
Install ffmpeg
1–3 min
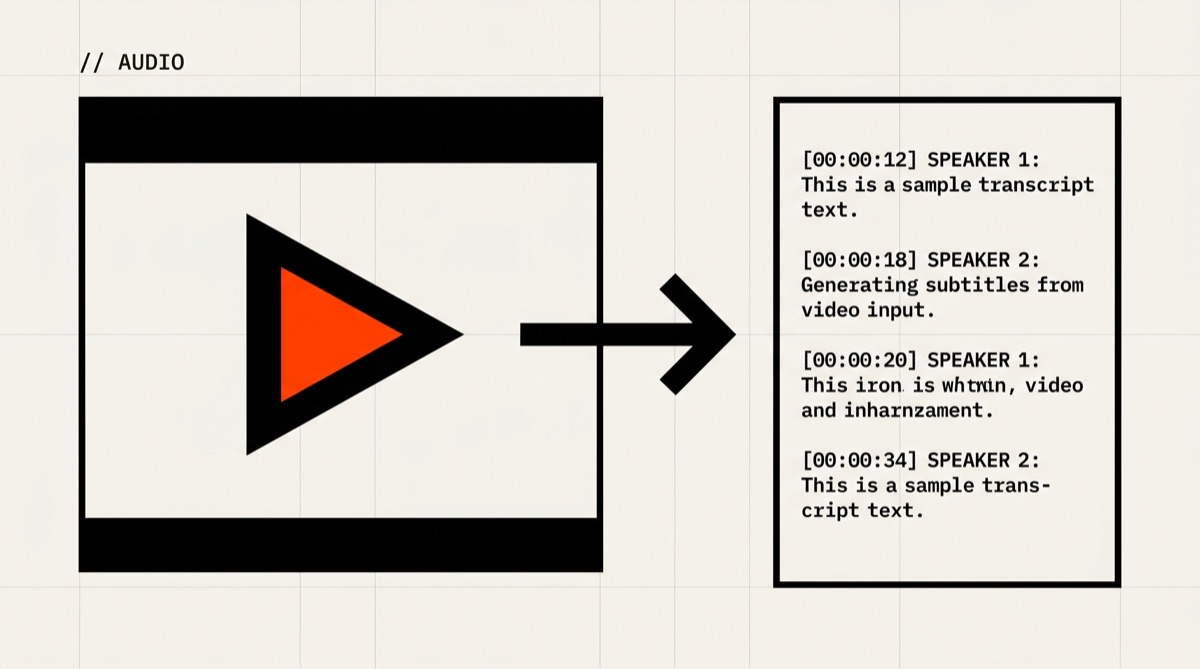
Whisper reads audio. ffmpegis the tool that opens almost any audio or video file and feeds it to Whisper. It is the most common “why isn't this working” in this guide. We install it first. This is the hardest step on Windows. Stick with it.
Terminal · mac
$ brew install ffmpeg
Don't have brew? Run this one-liner first:
Terminal · mac
$/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Verify it worked
$ ffmpeg -version
ffmpeg version 6.1 Copyright (c) 2000-2024 ...
built with Apple clang version 15.0.0 ...
ffmpeg version 6.1 Copyright (c) 2000-2024 ...
built with Apple clang version 15.0.0 ...
This might happen (Windows, very common)
ffmpeg is not recognized
'ffmpeg' is not recognized as an internal or external command
The exe is on your disk but Windows doesn't know where to find it. Add the folder containing ffmpeg.exe to your PATH. In Settings → search “Edit environment variables” → User variables → Path → New → paste the folder path (e.g. C:\ffmpeg\bin). Close every open terminal and open a new one — PATH changes do not apply to already-open shells.